Figure 2: The Mining Kernel System (MKS)
Over the past two decades there has been a huge increase in the amount of data being stored in databases as well as the number of database applications in business and the scientific domain. This explosion in the amount of electronically stored data was accelerated by the success of the relational model for storing data and the development and maturing of data retrieval and manipulation technologies. While technology for storing the data developed fast to keep up with the demand, little stress was paid to developing software for analysing the data until recently when companies realised that hidden within these masses of data was a resource that was being ignored. The huge amounts of stored data contains knowledge about a number of aspects of their business waiting to be harnessed and used for more effective business decision support. Database Management Systems used to manage these data sets at present only allow the user to access information explicitly present in the databases i.e. the data. The data stored in the database is only a small part of the 'iceberg of information' available from it. Contained implicitly within this data is knowledge about a number of aspects of their business waiting to be harnessed and used for more effective business decision support. This extraction of knowledge from large data sets is called Data Mining or Knowledge Discovery in Databases and is defined as the non-trivial extraction of implicit, previously unknown and potentially useful information from data [FRAW91]. The obvious benefits of Data Mining has resulted in a lot of resources being directed towards its development.
Almost in parallel with the developments in the database field, machine learning research was maturing with the development of a number of sophisticated techniques based on different models of human learning. Learning by example, cased-based reasoning, learning by observation and neural networks are some of the most popular learning techniques that were being used to create the ultimate thinking machine.
Figure 1: Data Mining
While the main concern of database technologists was to find efficient ways of storing, retrieving and manipulating data, the main concern of the machine learning community was to develop techniques for learning knowledge from data. It soon became clear that what was required for Data Mining was a marriage between technologies developed in the database and machine learning communities.
Data Mining can be considered to be an inter-disciplinary field involving concepts from Machine Learning, Database Technology, Statistics, Mathematics, Clustering and Visualisation among others.
So how does Data Mining differ from Machine Learning? After all the goal of both technologies is learning from data. Data Mining is about learning from existing real-world data rather than data generated particularly for the learning tasks. In Data Mining the data sets are large therefore efficiency and scalability of algorithms is important. As mentioned earlier the data from which data mining algorithms learn knowledge is already existing real-world data. Therefore, typically the data contains lots of missing values and noise and it is not static i.e. it is prone to updates. However, as the data is stored in databases efficient methods for data retrieval are available that can be used to make the algorithms more efficient. Also, Domain Knowledge in the form of integrity constraints is available that can be used to constrain the learning algorithms search space.
Data Mining is often accused of being a new buzz world for Database Management System (DBMS) reports. This is not true. Using a DBMS Report a company could generate reports such as:
However, using Data Mining techniques the following questions may be answered
Clearly, Data Mining provides added value to DBMS reports and answers questions that DBMS reports cannot answer.
2. Characteristics of a Potential Customer for Data Mining
Most of the challenges faced by data miners stem from the fact that data stored in real-world databases was not collected with discovery as the main objective. Storage, retrieval and manipulation of the data were the main objectives of the data being stored in databases. Thus most companies interested in data mining poses data with the following typical characteristics:
The sheer size of the databases in real-world applications causes efficiency problems. The noise in the data and heterogeneity cause problems in terms of accuracy of the discovered knowledge and complexity of the discovery algorithms required.
3. Aspects of Data Mining
In this section we discuss a number of issues that need to be addressed by any serious data mining package.
4. Classification of Data Mining Problems
Agrawal et. al [AGRA93] classify Data Mining problems into three categories :
Two approaches have been employed within machine learning to learn classifications. They are Neural Network based approaches and Induction based approaches. Both approaches have a number of advantages and disadvantages. Neural Networks may take longer to train than a rule induction approach but they are known to be better at learning to classify in situations where the data is noisy. However, as it is difficult to explain why a Neural Network made a particular classification they are dismissed as unsuitable for real Data Mining. Rule Induction based approaches to classification are normally Decision Tree based. Decision Trees can get very large and cumbersome when the training set is large, which is the case in Data Mining, and though they are not black boxes like Neural Networks become difficult to understand as well.
Both Neural Networks [ANAN95] and Tree Induction [AGRA92] techniques have been employed for Data Mining as well along with Statistical techniques [CHAN91].
if we have a table containing information about people living in Belfast, an association rule could be of the type
(Age < 25) Ù (Income > 10000) ® (Car_model = Sports)
This rule associates the Age and Income of a person to the type of car he drives.
Set oriented approaches AGRA93, AGRA94, AGRA95] developed by Agrawal et. al. are the most efficient techniques for discovery of such rules. Other approaches include attribute-oriented induction techniques [HAN 94], Information Theory based Induction [SMYT91] and Minimal-Length Encoding based Induction [PEDN91].
Another technique uses Dynamic Time Warping, a technique used
in the speech recognition field, to find patterns in temporal
data [BERN94].
5. A Data Mining Model
5.1 Data Pre-processing: As mentioned in section 2, data stored in the real-world is full of anomalies that need to be dealt with before sensible discovery can be made. This Data Pre-processing/ Cleansing may be done using visualisation or statistical tools. Alternatively, a Data Warehouse (see section 8.1) may be built prior to the Data Mining tools being applied.
Data Pre-processing involves removing outliers in the data, predicting and filling-in missing values, noise reduction, data dimensionality reduction and heterogeneity resolution. Some of the tools commonly used for data pre-processing are interactive graphics, thresholding and Principal Component Analysis.
5.2 Data Mining Tools: The Data Mining tools consist of the algorithms that automatically discover patterns from the pre-processed data. The tool chosen depends on the mining task at hand.
5.3 User Bias: The User is central to any discovery/ mining process. User Biases in the Data Mining model are a way for the User to direct the Data Mining tools to areas in the database that are of interest to the user. User Bias may consist of:
6. Data Mining Technologies
Various approaches have been used for Data Mining based on inductive learning [ IMAM93], Bayesian statistics [WUQ91], information theory [SMYT91], fuzzy sets [YAGE91], rough sets [ZIAR91], Relativity strength [BELL93], Evidence Theory [ANAN95] etc.
6.1 Machine Learning
To be able to make a machine mimic the intelligent behaviour of humans has been a long standing goal of Artificial Intelligence researchers who have taken their inspiration from a variety of sources such as psychology, cognitive science and neurocomputing.
Machine Learning paradigms can be classified into two classes: Symbolic and Non-symbolic paradigms. Neural Networks are the most common non-symbolic paradigm while rule-induction is a symbolic paradigm.
6.1.1 Neural Networks: Neural Networks is a Non-Symbolic paradigm of Machine Learning that finds its inspiration from Neuroscience. The realisation that most Symbolic Learning Paradigms are not satisfactory in a number of domains e.g. pattern recognition, that are regarded by humans as trivial lead to research into trying to model the human brain.
The human brain consists of a network of approximately 1011 neurones. Each biological neurone consists of a number of nerve fibres called dendrites connected to the cell body where the cell nucleus is located. The axon is a long, single fibre that originates from the cell body and branches near its end into a number of strands. At the ends of these strands are the transmitting ends of the synapse that connect to other biological neurones through the receiving ends of the synapse found on dendrites as well as the cell body of biological neurones. A single axon typically makes thousands of synapses with other neurones. The transmission process is a complex chemical process which effectively increases or decreases the electrical potential within the cell body of the receiving neurone. When this electrical potential reaches a threshold value (action potential) it enters it's excitatory state and is said to fire. It is the connectivity of the neurones that give these simple 'devices' their real power. The figure above shows a typical biological neurone.
An Artificial Neurone [HERT91] (or processing elements, PE) are highly simplified models of the biological neurone (see figure). As in biological neurones an artificial neurone has a number of inputs, a cell body (consisting of the summing node and the Semi-Linear function node in the figure) and an output which can be connected to a number of other artificial neurones.
Neural Networks are densely interconnected networks of PE's together with a rule to adjust the strength of the connections between the units in response to externally supplied data. Using neural networks as a basis for a computational model has its origins in pioneering work conducted by McCulloch and Pitts in 1943 [McCU43]. They suggested a simple model of a neurone that commuted the weighted sum of the inputs to the neurone and output a 1 or a 0 according to weather the sum was over a threshold value or not. A zero output would correspond to the inhibitory state of the neurone while a 1 output would correspond to the excitatory state of the neurone. But the model was far from a true model of a biological neurone as for a start the biological neurones output is a continuous function rather than a step function. The step function has been replaced by other more general, continuous functions called activation functions. The most popular of these is the sigmoid function defined as:
f(x) = 1/(1+e-x)
The overall behaviour of a network is determined by its connectivity rather than by the detailed operation of any element. Different topologies for neural networks are suitable for different tasks e.g. Hopfield Networks for optimization problems, Multi-layered Perceptron for classification problems and Kohonen Networks for data coding.
There are three main ingredients to a neural network :
the neurones and the links between them
the algorithm for the training phase
a method for interpreting the response from the network in the testing phase
The learning algorithms used are normally iterative e.g. back-propagation algorithm attempting to reduce the error in the output of the network. Once the error is reduced (not necessarily minimum) the network can be used to classify other unseen objects.
Though neural networks seem an attractive concept they have a number of disadvantages. Firstly, the learning process is very slow and compared to other learning methods. The learned knowledge is in the form of a network and it is difficult for a user to interpret it (the same is a disadvantage of using decision trees). User intervention in the learning process, interactively is difficult to incorporate which is normally required in Data Mining applications. However, neural networks are known to perform better that symbolic learning techniques in noisy data found in most real-world data sets.
6.1.2 Rule Induction: Automating the process of learning has enthralled AI researchers for some years now. The basic idea is to build a model of the environment using sets of data describing the environment. The simplest model clearly is to store all the states of the environment along with all the transitions between them over time. For example, a chess game may be modelled by storing each state of the chess board along with the transitions from one state to the other. But the usefulness of such a model is limited as the number of states and transitions between them are infinite. Thus, it is unlikely that a state that occurs in the future would match, exactly, a state from the past. Thus, a better model would be to store abstractions / generalizations of the states and the associated transitions. The process of generalization is called Induction.
Each generalization of the states is called a class and has a class description associated with it. The class description defines the properties that a state must have to be a member of the associated class.
The process of building a model of the environment using examples of states of the environment is called Inductive Learning. There are two basic types of inductive learning :
Supervised Learning
Unsupervised Learning
In Supervised Learning the system is provided with examples of states and class labels for each of the
examples defining the class that the example belongs to. Supervised Learning techniques are then used on the examples to find a description for each of the classes. The set of examples is called the training data set. Supervised learning may be classified into Single Class Learning and Multiple Class Learning.
In Single Class Learning the supervisor defines a single class by providing examples of states belonging to that class (positive examples). The supervisor may also provide examples of states that do not belong to that class (negative examples). The inductive learning algorithm then constructs a class description for the class that singles out instances of that class from other examples.
In Multiple Class Learning the examples provided by the supervisor belong to a number of classes. The inductive learning algorithm constructs class description for each of the classes that distinguish states belonging to one class from those belonging to another.
In Unsupervised Learning the classes are not provided by a supervisor. The inductive learning algorithm has to identify the classes by finding similarities between different states provided as examples. This process is called learning by observation and discovery.
6.2 Statistics: Statistical techniques may be employed for data mining at a number of stages of the mining process. Infact statistical techniques have been employed by analysts to detect unusual patterns and explain patterns using statistical models. However, using statistical techniques and interpreting their results is difficult and requires a considerable amount of knowledge of statistics. Data Mining seeks to provide non-statisticians with useful information that is not difficult to interpret. We know discuss how statistical techniques can be used within Data Mining.
(1) Data Cleansing: The presence of data which are erroneous or irrelevant (outliers) may impede the mining process. Whilst such data therefore need to be distinguished, this task is particularly sensitive, as some outliers may be of considerable interest in providing the knowledge that mining seeks to find: 'good' outliers need to be retained, whilst 'bad' outliers should be removed. Bad outliers may arise from sources such as human or mechanical errors in experimental measurement, from the failure to convert measurements to a consistent scale, or from slippage in time-series measurements. Good outliers are those outliers that may be characteristic of the real world scenario being modelled. While these are often of particular interest to users, knowledge about them may be difficult to come by and is frequently more critical than knowledge about more commonly occurring situations. The presence of outliers may be detected by methods involving thresholding the difference between particular attribute values and the average, using either parametric or non-parametric methods.
(2) Exploratory Data Analysis: Exploratory Data Analysis (EDA) concentrates on simple arithmetic and easy-to-draw pictures to provide Descriptive Statistical Measures and Presentation, such as frequency counts and table construction (including frequencies, row, column and total percentages), building histograms, computing measures of location (mean, median) and spread (standard deviation, quartiles and semi inter-quartile range, range).
(3) Data Selection: In order to improve the efficiency and increase the time performance of data analysis, it is necessary to provide sampling facilities to reduce the scale of computation. Sampling is an efficient way of finding association rules, and resampling offers opportunities for cross-validation. Hierarchical data structures may be explored by segmentation and stratification.
(4) Attribute re-definition: We may define new variables which are more meaningful than the previous e.g. Body Mass Index (BMI) = Weight / Height squared. Alternatively we may want to change the granularity of the data e.g. age in years may be grouped into age groups 0-20 years, 20-40 years, 40-60 years, 60+ years.
Principal Component Analysis (PCA) is of particular interest to Data Mining as most Data Mining algorithms have linear time complexity with respect to the number of tuples in the database but are exponential with respect to the number of attributes of the data. Attribute Reduction using PCA thus provides a facility to account for a large proportion of the variability of the original attributes by considering only relatively few new attributes (called Principal Components) which are specially constructed as weighted linear combinations of the original attributes. The first Principal Component (PC) is that weighted linear combination of attributes with the maximum variation; the second PC is that weighted linear combination which is orthogonal to the first PC whilst maximising the variation, etc. The new attributes formed by PCA may possibly themselves be assigned individual meaning if domain knowledge is invoked, or they may be used as inputs to other Knowledge Discovery tools. The facility for PCA requires the partial computation of the eigensystem of the correlation matrix, as the PC weights are the eigenvector components, with the eigenvalues giving the proportions of the variance explained by each PC.
(5) Data Analysis: Statistics provides a number of tools for data analysis some of which may be employed within Data Mining. These include:
6.3 Database Approaches - Set Oriented Approaches: Set-oriented approaches to data mining attempt to employ facilities provided by present day DBMSs to discover knowledge. This allows the use of years of research into database performance enhancement to be used within Data Mining processes. However, SQL is very limited in what it can provide for Data Mining and therefore techniques based solely on this approach are very limited in applicability. Though these techniques have shown that certain aspects of Data Mining can be performed within the DBMS efficiently, providing a challenge for researchers into investigating how the data mining operations can be divided into DBMS operations and non-DBMS operations to make the most of both worlds.
6.4 Visualisation: Visualisation techniques are used within the discovery process at two levels. Firstly, visualising the data enhances exploratory data analysis. Exploratory Data Analysis is useful for data pre-processing allowing the user to identify outliers and data subsets of interest. Secondly, Visualisation may be used to make underlying patterns in the database more visible. NETMAP, a commercially available Data Mining Tool derives most of its power from this pattern visualisation technique.
7. Knowledge Representation
7. 1 Neural Networks (see section 5.1.1)
7.2 Decision Tree
fig. 2 : An example Decision Tree
ID3 [QUIN86] is probably the most well known classification algorithms in machine learning that uses decision trees. ID3 belongs to the family of TDIDT algorithms (Top-Down Induction of Decision Trees) and has undergone a number of enhancements since it's conception e.g. ACLS [PATE83], ASSISTANT [KONO84].
A Decision Tree is a tree based knowledge representation methodology used to represent classification rules. The leaf nodes represent the class labels while other nodes represent the attributes associated with the objects being classified. The branches of the tree represent each possible value of the attribute node from which they originate. Figure 2 shows a typical decision tree [QUIN86].
Once the decision tree has been built using a training set of data it may be used to classify new objects. To do so we start at the root node of the tree and follow the branches associated with the attribute values of the object until we reach a leaf node representing the class of the object.
Clearly, for a training set of examples there are a large number of possible decision trees that could be generated. The basic idea is to pick the decision tree that would correctly classify the most unknown examples (which is the essence of the induction process). One way of doing this is to generate all the possible decision trees for the training set and picking the simplest tree. Alternatively, the tree could be built in such a way that the final tree is the best. In ID3 they use an information theoretic measure for 'gain in information' by using a particular attribute as a node to decide on an attribute for a particular node.
Though decision trees have been used successfully in a number of algorithms, they have a number of disadvantages. Firstly, even for small training sets decision trees can be quite large and thus opaque. Quinlan [QUIN87] points out that it is questionable whether opaque structures like decision trees can be described as knowledge, no matter how well they function. Secondly, in the presence of missing values for attributes of objects in the test data set, trees can have a problem with performance. Also the order of attributes in the tree nodes can have an adverse affect on performance.
The main advantage of decision trees is their execution efficiency many due to their simple and economical representation and ability to perform even though they lack the expressive power of semantic networks or other first order logic methods of knowledge representation.
7.3 Rules
Rules are probably the most common form of data representation. A rule is a conditional statement that specifies an action for a certain set of conditions, normally represented as X ® Y. The action, Y, is normally called the consequent of the rule and the set of conditions, X, its antecedent. A set of rules is an unstructured group of IF.. THEN statements.
The popularity of rules as a method of knowledge representation is mainly due to their simple form. They are easily interpreted by humans as they are a very intuitive and natural way of representing knowledge, unlike decision trees and neural networks. Also as a system of rules is unstructured, it is less rigid, which can be advantageous at the early stages of the development of a knowledge based system.
But representing knowledge as rules has a number of disadvantages. Rules lack variation and are unstructured. Their format is inadequate to represent many types of knowledge e.g. causal knowledge. As the number of rules in the system increases the performance of the system decreases and the system becomes more difficult to maintain and modify. New rules cannot be added arbitrarily to the system as they may contradict existing rules of the system leading to erroneous conclusions. The degradation in performance of a rule based system is not graceful.
The lack of structure in rule based representations makes the modelling of the real-world difficult if not impossible. Thus, a more organized and structured representation for knowledge is desirable that can make partial inferences and degrade gracefully with size.
7.4 Frames
Frames are a template for holding clusters of related knowledge about a particular, narrow subject, which is often the name of the frame. The clustering of related knowledge is a more natural way of representing knowledge as a model of the real-world.
Each frame consists of a number of slots that contain attributes, rules, hypotheses and graphical information related to the object represented by the frame. These slots may be frames in their own right, giving the frames a hierarchical structure. Relationships between frames are taxonomic and therefore a frame inherits properties of its 'parent frames'. Thus, if the required information is not contained in a frame the next frame up in the hierarchy is searched.
Due to the structuring of knowledge in frames, representing knowledge in frames is more complex than a rule-based representation.
8. Related Technologies
8.1 Data Warehousing - "to manage the data that analyses your business"
On-line Transaction Processing (OLTP) systems are inherently inappropriate for decision support querying and, therefore, the need for Data Warehousing. A data warehouse is a Relational Database Management System designed to provide for the needs of decision makers rather than the needs of transaction processing systems. Thus, a data warehouse provides data in a form suitable for business decision support. More specifically, a Data Warehouse allows
A Data Warehouse brings together large volumes of business information obtained from transaction processing and legacy operational systems. The information is cleansed and transformed so that it is complete and reliable and it is stored over time so that trends can be identified. Data Warehouses are normally employed in one of two roles:
OLTP systems are designed to capture, store and manage day-to-day operations. The raw data collected in OLAP systems exists in a number of different formats like hierarchical databases, flat files, COBOL datasets, in legacy systems keeping them out of reach from business decision makers.
Typically Data Warehousing software has to deal with large updates with narrow batch windows. Getting the data into the warehouse and fully preparing it for use is the key update to the warehouse. Therefore, a warehouse must provide for the following requirements:
Additionally, a Data Warehouses must:
A Data Warehouse presents a dimensional view of the data. Users expect to view this data from different perspectives or dimensions. Such functionality is provided by On-line Analytical Processing. Two general approaches have emerged to meet this requirement of OLAP
Red Brick Warehouse V(Very Large Data Warehouse Support)P(Parallel Query Processing)T(Time Based Data Management)
Consists of three components
Example query: What are the top ten products sold during the second quarter of 1993 and what were their rankings by dollars and units sold?
8.2 On-line Analytical Processing
Today a business enterprise can prosper or fail based on the availability of accurate and timely information. The Relational Model was introduced in 1970 by E. F. Codd in an attempt to allow the storage and manipulation of large data sets about the day-to-day working of a business. However, just storing the data is not enough. Techniques are required to help the analyst infer information from this data that can be used by the business enterprise to give it an edge over the competition.
Relational Database Management System (RDBMS) products are not very good at transforming data stored in OLTP applications and converting it into useful information. A number of reasons contribute to why RDBMSs are not suitable for business analysis:
Complex statistical functionality was never intended to be provided along with the RDBMS. Providing such functionality was left to the user-friendly end-user products like spreadsheets that were to act as front ends to the RDBMS. Though spreadsheets have provided a certain amount of functionality required by business analysts none address the need for analysing the data according to its multiple dimensions.
Any product that intends to provide such functionality to business analysts must allow the following:
On-line Analytical Processing (OLAP) is the name given, by E. F. Codd (1993), to the technologies that attempt to address these user requirements. Codd defined OLAP as "the dynamic synthesis, analysis and consolidation of large volumes of multi-dimensional data". Codd provided 12 rules/ requirements of any OLAP system. These were:
Nigle Pendse provided another definition of OLAP which, unlike Codds definition, does not mix technology prescriptions with application requirements. He defined OLAP as "Fast Analysis of Shared Multidimensional Information". Within the definition:
9. State of the Art and Limitations of Commercially Available Products
9.1 End-User Products
Most end-user products available in the market do not address many of the aspects of data mining enumerated in section 3. Infact, these packages are really machine learning packages with added facilities for accessing databases. Having said that they are powerful tools that can be very useful given a clean data set. However clean data sets are not found in real-world applications and cleansing large data sets manually is not possible.
In this section we discuss two end-user products available in the UK. However, a much larger number of so called "data mining tools" exist in the market.
9.1.1 CLEMENTINE
This package supplied by ISL Ltd., Basingstoke, England is a very easy to use package for "data mining". The interface has been built with the intention of making it "as easy to use as a spreadsheet". CLEMENTINE uses a Visual Programming Interface for building the discovery model and performing the learning tasks.
Accessible Data Sources: ASCII File format, Oracle, Informix, Sybase and Ingres.
Discovery Paradigms: Decision Tree Induction and Neural Network (Mutli Layer Perceptron).
Data Visualisation: Through interactive histograms, scatter plots, distribution graphs etc.
Data Manipulation: Sampling, Derive New Attributes, Filter Attributes
Hardware Platforms: Most Unix Workstations
Statistical Functionality: Correlations, Standard Deviation etc.
Deploying Applications: A Trained Neural Network or Decision Tree may be exported as C.
Data Mining Tasks Suitability: Classification problems with clean data sets available.
Consultancy: Available
9.1.2 DataEngine
This package is supplied by MIT GmbH, Germany. It also provides a Visual Programming interface.
Accessible Data Sources: ASCII File format, MS-Excel
Discovery Paradigms: Fuzzy Clustering, Fuzzy Rule Induction, Neural Network (Multi-Layered Perceptron, Kohonen Self-Organising Map), Neuro-Fuzzy Classifier
Data Visualisation: Scatter and line plots, Bar charts and Area plots
Data Manipulation: Missing Data Handling, Selection, Scaling
Hardware Platforms: Most UNIX Workstations & Windows.
Statistical Functionality: Correlation, Linear Regression etc.
Deploying Applications: DataEngine ADL allows the integration of classifiers into other software Environments
Data Mining Tasks Suitability: Classification
Consultancy: Available
9.2 Consultancy Based Products
9.2.1 SGI
Silicon Graphics provide "Tailored Data Mining Solutions" which include Hardware support in the form of CHALLENGE family of database servers and software support in the form of Data Warehousing and Data Mining software. The CHALLENGE servers provide unique Data Visualisation capabilities an area that Silicon Graphics are recognised as leaders. The Interface provided by SGI allows you to "fly" through visual representations of your data allowing you to identify important patterns in your data and directing you to the next question you should ask within your analysis!
Apart from Visualisation, SGI provides facilities for Profile Generation and Mining for Association Rules.
9.2.2 IBM
IBM provide a number of tools to give users a powerful interface to Data Warehouses.
9.2.2.1 IBM Visualizer: Provides a powerful and comprehensive set of ready to use building blocks and development tools that can support a wide range of end-user requirements for query, report writing, data analysis, chart/ graph making and business planning.
9.2.2.2 Discovering Association Patterns: IBMs Data Mining group at Almaden pioneered research into efficient techniques for discovering associations in buying patterns in supermarkets. There algorithms have been successfully employed in supermarkets in the USA to discover patterns in the supermarket data that could not have been discovered without data mining.
9.2.2.3 Segmentation or Clustering: Data Segmentation is the process of separating data tuples into a number of sub-groups based on similarities in their attribute values. IBM provides two solutions based on two different discovery paradigms: Neural Segmentation and Binary Segmentation. Neural Segmentation is based on a Neural Network technique called self-organising maps. Binary Segmentation was developed at IBMs European Centre for Applied Mathematics. It is based on a technique called relational analysis. This technique was developed to deal with binary data.
Applications: Basket Analysis
10. Case Studies and Data Mining Success Stories
Case Study 1: Health Care Analysis using Health-KEFIR
KEFIR (Key Findings Reporter) is a domain independent system for discovering and explaining key findings i.e. deviations developed by GTE labs.
KEFIR consists of four main parts:
KEFIR starts by discovering deviations in the predefined measures for the top sector and then discovers deviations in the sub-sectors that seem interesting.
These two factors together give a value for potential saving which is used to rank the deviations.
KEFIR needs to be tailored to the specific domain. The Healthcare application resulted in Health-KEFIR, a version specific to Healthcare. The success of KEFIR-Health proves that Data Mining solutions need to be tailored to the specific domain and specific solutions to mining tasks are more realistic than multi-purpose solutions.
Case Study 2: Mass Appraisal for Property Taxation
The Data Set consisted of 416 data items. One in three items were selected as the holdout sample
For each property the following variables were used as input to the Neural Network:
The goal was to predict the house price based on the other attributes of the houses. We used a Neural Network for the prediction and achieved an accuracy of approximately 82% with a mean error of approximately 15%. We also explored using a Rule Induction approach. The accuracy achieved by the Neural Network was greater than that achieved through rule induction.
Using simple data visualisation outliers in the data were spotted and removed from the data. The neural network was trained on the remaining dataset. The predictive accuracy of the network improved from 82% to approximately 93% with the mean error reducing to approximately 7.8%.
Case Study 3: Policy Lapse/Renewal Prediction
A Large Insurance Company had collected a large amount of data on its motor insurance customers. Using this data, the company wanted to be able to predict in advance which policies were going to lapse and which ones were going to be renewed when they near expiry. The advantage of such a prediction is obvious. As the competition increases in the business world customer retention has become an important issue. The insurance company wanted to target new services at their customers to woo them into renewing their policies and not moving to other insurance companies. Clearly, rather than targeting customers that are going to renew their policy anyway it would be better to target customers who are more likely to lapse their policy. Data Mining provided the solution for the company.
Of the 34 different attributes stored for each policy we picked 12 attributes that seemed to have an effect on whether or not the policy was going to lapse or not. Using a neural network we achieved a predictive accuracy of 71% and using rule induction based techniques we were able to identify attributes of an insurance policy that was going to lapse. The whole exercise took approximately 3 weeks to complete. The accuracy achieved by Data Mining equalled the accuracy achieved by the companies statisticians who undoubtedly spent many more man months on their statistical models.
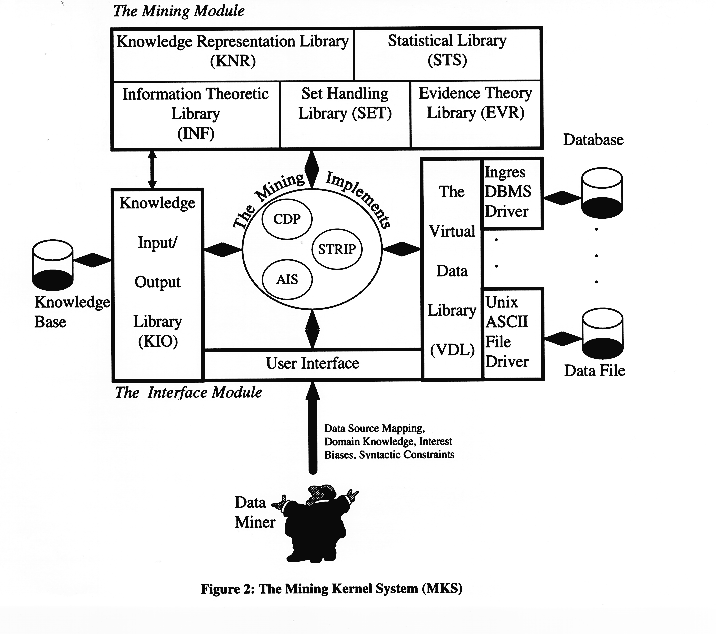
11. The Mining Kernel System: The University of Ulster's perspective
The Mining Kernel System (MKS) being developed in the authors' laboratory embodies the inter-disciplinary nature of Data Mining by providing facilities from Statistics, Machine Learning, Database Technology and Artificial Intelligence. The functionality provided by MKS forms a strong foundation for building powerful Data Mining implements required to tackle what is clearly recognised to be a complex problem.
MKS is a set of libraries implemented by the authors to remove the mundane, repetitive tasks like data access, knowledge representation and statistical functionality from Data Mining so as to allow the user to concentrate on the more complex aspects of the discovery algorithms being implemented. In this section we describe the motivation behind each of the libraries within MKS along with brief descriptions of these libraries.
Figure 2 shows the architecture of MKS.
Figure 2: The Mining Kernel System (MKS)
At present MKS has 7 libraries providing Data Mining facilities. The facilities provided by MKS may be split into two main modules: The Interface Module and the Mining Module.
The Interface Module provides facilities for Mining algorithms to interact with the environment. MKS has three distinct interfaces to the outer world - the User using the User Interface, the Data Interface using the VDL Library and the Knowledge Interface using the KIO Library. Information provided by the user using the user interface include the data view in the form of the Data Source Mapping file (see section 2.1.2), Domain Knowledge, Syntactic Constraints e.g. antecedent attributes of interest and Support, Uncertainty and Interestingness thresholds.
The Mining module provides core facilities required by most mining algorithms. At present the Mining module of MKS consists of 5 Libraries that provide facilities from Conventional Statistics, Machine Learning and Artificial Intelligence. The libraries within this module of MKS are: the Statistical Library (STS), the Information Theoretic Library (INF), the Knowledge Representation Library (KNR), the Set Handling Library (SET) and the Evidence Theory Library (EVR).
References
[AGRA92] Agrawal R, Ghosh S, Imielinski T, Iyer B and Swami A, An interval classifier for database mining applications, Proc of 18th Int'l Conf. on VLDB, pp 560-573, 1992.
[AGRA93] Agrawal R, Imielinski T and Swami A, Database mining: A performance perspective, IEEE Transactions on Knowledge and Data Engineering, Special issue on Learning and Discovery in Knowledge-Based Databases, 1993.
[AGRA93a] Agrawal R, Imielinski T and Swami A, Mining association rules between sets of items in large databases, Proc of the ACM SIGMOD Conf. on Management of Data, 1993.
[AGRA93b] R. Agrawal, C. Faloutsos, A. Swami. Efficient similarity search in sequence databases. Proc. of the 4th International Conference on Foundations of Data Organisation and Algorithms, 1993.
[AGRA94] R. Agrawal, R. Srikant. Fast Algorithms for Mining Association Rules in Large Databases. Proc. of VLDB94, Pg. 487 - 499, 1994.
[AGRA95] R. Srikant, R. Agrawal. Mining Generalized Association Rules. Proc. of VLDB95.
[AGRA95a] Fast Similarity Search in the Presence of Noise, Scaling and Translation in Time-Series Databases. Pro. of VLDB95.
[ANAN95] S.S. Anand, D.A. Bell and J.G. Hughes, A General Framework for Data Mining Based on Evidence Theory, Provisionally accepted by Data and Knowledge Engineering Journal.
[BELL93] D. A. Bell, From Data Properties to Evidence, IEEE Transactions on Knowledge and Data Engineering, Vol. 5, No. 6, Special Issue on Learning and Discovery in Knowledge - Based Databases, December, 1993.
[BERN94] D. J. Berndt, J. Clifford. Using dynamic time warping to find patterns in time series. KDD94: AAAI Workshop on Knowledge Discovery in Databases, Pg. 359 - 370, July, 1994.
[CHAN91] K. C. C. Chan, A. K. C. Wong. A Statistical Technique for Extracting Classificatory Knowledge from Databases. Knowledge Discovery in Databases, Pg. 107 - 124, AAAI/MIT Press 1991.
[FRAW91] W. J. Frawley, G. Piatetsky-Shapiro and C. J. Matheus, Knowledge Discovery in Databases : An Overview Knowledge Discovery in Databases, Pg. 1 - 27, AAAI/MIT Press 1991.
[HAN94] J. Han. Towards efficient induction mechanisms in database systems. Theoretical Computer Science 133, Pg. 361 - 385, 1994.
[IMAM93] I. F. Imam, R. S. Michalski and L. Kershberg, Discovering Attribute Dependencies in Databases by Integrating Symbolic Learning and Statistical Techniques, Working Notes of the Workshop in Knowledge Discovery in Databases, AAAI-93, 1993.
[LU95] H. Lu, R. Setiono, H. Liu. NeuroRule: A Connectionist Approach to Data Mining. Proc. of VLDB95.
[PEND91]E. P. D. Pendault. Minimal-Length Encoding and Inductive Inference. Knowledge Discovery in Databases, Pg. 71 - 92, AAAI/MIT Press 1991.
[SMYT91] ] P. Smyth and R. M. Goodman, Rule Induction Using Information Theory, Knowledge Discovery in Databases, Pg. 159 - 176, AAAI/MIT Press 1991.
[WUQ91] Q. Wu, P. Suetens and A. Oosterlinck, Integration of Heuristic and Bayesian Approaches in a Pattern - Classification System, Knowledge Discovery in Databases, Pg. 249 - 260, AAAI/MIT Press 1991.
[YAGE91] R. R. Yager, On Linguistic Summaries of Data, Knowledge Discovery in Databases, Pg. 347 - 366 AAAI/MIT Press 1991.
[ZIAR91] W. Ziarko, The Discovery, Analysis and Representation of Data Dependencies in Databases, Knowledge Discovery in Databases, Pg. 195 - 212, AAAI/MIT Press 1991.