DOCUMENTATION - DEMO EXECUTION
Introduction
The presented system's purpose is to discriminate an audio stream into speech and music. The system has been test on audio streams from on-line radio recordings, but it can be similarly used for any other audio stream.

Figure 1: GUI when the application is loaded (click on image to enlarge).
Loading a file
To load a file simply press the "Load" button as shown in the figures. When that button is pressed, a "Open File" dialog is appeared. Use this dialog to select any wav file. In the future, other audio formats could be supported. When the file is loaded, some basic information for the audio signal (e.g. sampling rate) is presented (see figure 2).Segmentation - Stage 1
When the file is loaded, the user can start running the segmentation algorithm, by pressing "Step 1" button. The 1st step of the system is a fast algorithm that detects speech and music segments with a high precision rate (i.e. only some segments with high classification probability are extracted). At the end of this step, some segments (usually 10%-50% of the whole audio stream) are left unclassified. These segments will be segmented and classified in step 2. When the 1st step finishes a visual representation of the segmented audio stream is presented. Each color corresponds to a different audio label (speech, music or unclassified).Segmentation - Stage 2
The 2nd stage of the sytem is consisted of the main segmentation algorithm, which is a hybrid Hidden Markov Model and Bayesian Network algorithm. To execute this step press button "Step 2". At this stage, each segment which was left unclassified by stage 1, is segmented and classified. This is the most time consuming stage, and you may wait some time until it finishes. When the stage is completed, some results are presented in the GUI (see in the "Results Explanation" paragraph).Segmentation - Stage 3
The last stage of the segmentation process is a post-processing stage for repairing some misclassified small segments and some segment's limits. A Bayesian Network approach is used for this purpose. When that stage is finished, the final results are presented (the previous results, from stage 2 are replaced by the new ones). Furthermore, the elapsed times of the algorithm's stages are presented.
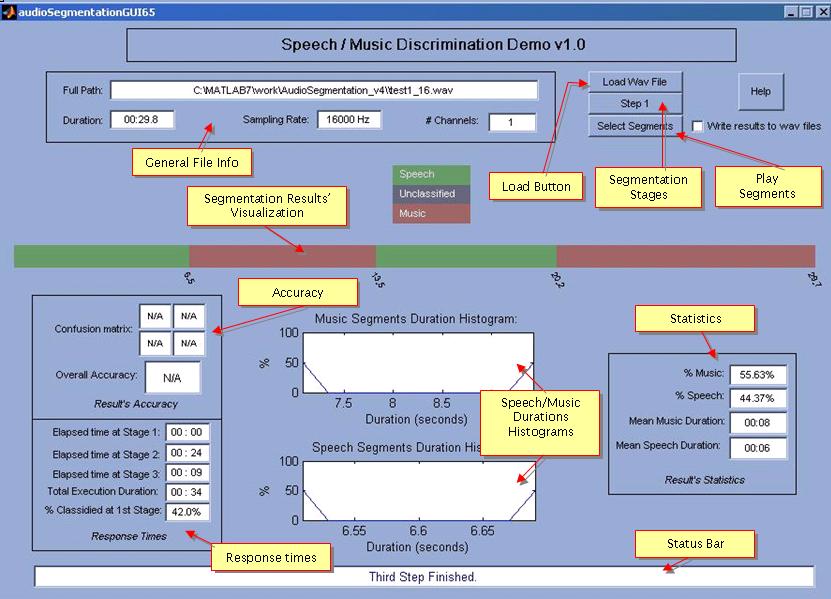
Figure 2: GUI after the 3rd stage is completed (click on image to enlarge).
Results Explanation
IMPORTANT: After 1/9/2007, the demo also produces a mat file named [wavFileName]_labels.mat which contains a variable called flagsFinal. This is an array containing the flags (0 for speech and 1 for music) for each short-term window (50ms long).
The following results are displayed in the dialog of the GUI:
- Results Accuracy:
- Overall Accuracy: The percentage of the audio data that was correctly classified.
- Confusion Matrix: Each element C(i,j) of the confusion matrix corresponds to the percentage of data whose true class label was i and was classified to class j. It is obvious that the overall accuracy is equal to C(1,1) + C(2,2). In our case the 1st class corresponds to music and the 2nd to speech. Therefore, for example the value C(1,2) is the % of data that were classified as speech, though their true class laber was music.
- Results Statistics:
- Mean music / speech segments duration (in seconds).
- Histograms of the music and speech segments' duration.
- Percentage of the data classified as speech or music.
- Response times:
- Ellapsed times for all 3 stages and total ellapsed time.
- % of the data classified in the 1st stage.