Ένας πόρος, όπως, για παράδειγμα μία δημοσίευση, ευρετηριάζεται σε τρία βήματα.
- Βήμα 1:
- Ο πάροχος
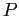 κατασκευάζει μία δημοσίευση
κατασκευάζει μία δημοσίευση
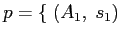 ,
,
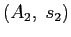 ,
,  ,
,
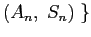 που αποτελεί την περιγραφή του πόρου και αποστέλλει το μήνυμα
που αποτελεί την περιγραφή του πόρου και αποστέλλει το μήνυμα
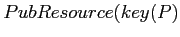 ,
, 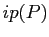 ,
, 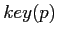 ,
, 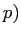 στο σημείο πρόσβασής του
στο σημείο πρόσβασής του 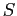 .
.
- Βήμα 2:
- Ο
προωθεί το
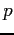 στους κατάλληλους υπερ-κόμβους σύμφωνα με τα επόμενα. Έστω ότι
στους κατάλληλους υπερ-κόμβους σύμφωνα με τα επόμενα. Έστω ότι
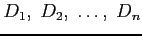 είναι τα σύνολα που αποτελούνται μόνο από τις διαφορετικές λέξεις στα
είναι τα σύνολα που αποτελούνται μόνο από τις διαφορετικές λέξεις στα
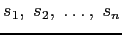 αντίστοιχα. Τότε το
αποστέλλεται σε όλους τους υπερ-κόμβους με αναγνωριστικά που βρίσκονται στη λίστα
αντίστοιχα. Τότε το
αποστέλλεται σε όλους τους υπερ-κόμβους με αναγνωριστικά που βρίσκονται στη λίστα
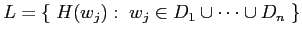 3.1. Το πρωτόκολλο κατάθεσης εγγυάται ότι το σύνολο
3.1. Το πρωτόκολλο κατάθεσης εγγυάται ότι το σύνολο 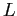 θα είναι ένα υπερσύνολο των αναγνωριστικών των υπερ-κόμβων που είναι υπεύθυνοι για επερωτήσεις που ταιριάζουν με το
. Στη συνέχεια, ο
αφαιρεί τα διπλότυπα αναγνωριστικά και ταξινομεί την λίστα
κατά αύξουσα σειρά. Με αυτόν τον τρόπο το
περιέχει λιγότερα αναγνωριστικά από τις διπλότυπες λέξεις του συνόλου
θα είναι ένα υπερσύνολο των αναγνωριστικών των υπερ-κόμβων που είναι υπεύθυνοι για επερωτήσεις που ταιριάζουν με το
. Στη συνέχεια, ο
αφαιρεί τα διπλότυπα αναγνωριστικά και ταξινομεί την λίστα
κατά αύξουσα σειρά. Με αυτόν τον τρόπο το
περιέχει λιγότερα αναγνωριστικά από τις διπλότυπες λέξεις του συνόλου
 , αφού κάθε υπερ-κόμβος δύναται να είναι υπεύθυνος για περισσότερες από μία λέξεις που περιέχονται στο έγγραφο προς δημοσίευση. Έχοντας υπολογίσει το
, ο
ευρετηριάζει το
δημιουργώντας το μήνυμα
, αφού κάθε υπερ-κόμβος δύναται να είναι υπεύθυνος για περισσότερες από μία λέξεις που περιέχονται στο έγγραφο προς δημοσίευση. Έχοντας υπολογίσει το
, ο
ευρετηριάζει το
δημιουργώντας το μήνυμα
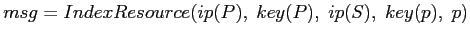 και αποστέλλοντάς το στους κατάλληλους κόμβους με τη συνάρτηση
και αποστέλλοντάς το στους κατάλληλους κόμβους με τη συνάρτηση
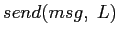 .
.
- Βήμα 3:
- Τέλος, κάθε υπερ-κόμβος
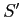 που παραλαμβάνει το μήνυμα
που παραλαμβάνει το μήνυμα 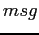 αποθηκεύει το
σε ένα ανεστραμμένο ευρετήριο3.2 το οποίο θα διευκολύνει το ταίριασμά τους με τις στιγμιαίες επερωτήσεις που θα παραλάβει αργότερα ο
από έναν πελάτη.
αποθηκεύει το
σε ένα ανεστραμμένο ευρετήριο3.2 το οποίο θα διευκολύνει το ταίριασμά τους με τις στιγμιαίες επερωτήσεις που θα παραλάβει αργότερα ο
από έναν πελάτη.
Charalampos Nikolaou
2008-04-02